Free Open-Source Artificial Intelligence
Meta has released and open-sourced **Llama 3.1** in three different sizes: **8B**, **70B**, and **405B** This new Llama iteration and update brings state-of-the-art performance to open-source ecosystems. If you've had a chance to use Llama 3.1 in any of its variants - let us know how you like it and what you're using it for in the comments below! ## Llama 3.1 Megathread > For this release, we evaluated performance on over 150 benchmark datasets that span a wide range of languages. In addition, we performed extensive human evaluations that compare Llama 3.1 with competing models in real-world scenarios. Our experimental evaluation suggests that our flagship model is competitive with leading foundation models across a range of tasks, including GPT-4, GPT-4o, and Claude 3.5 Sonnet. Additionally, our smaller models are competitive with closed and open models that have a similar number of parameters. 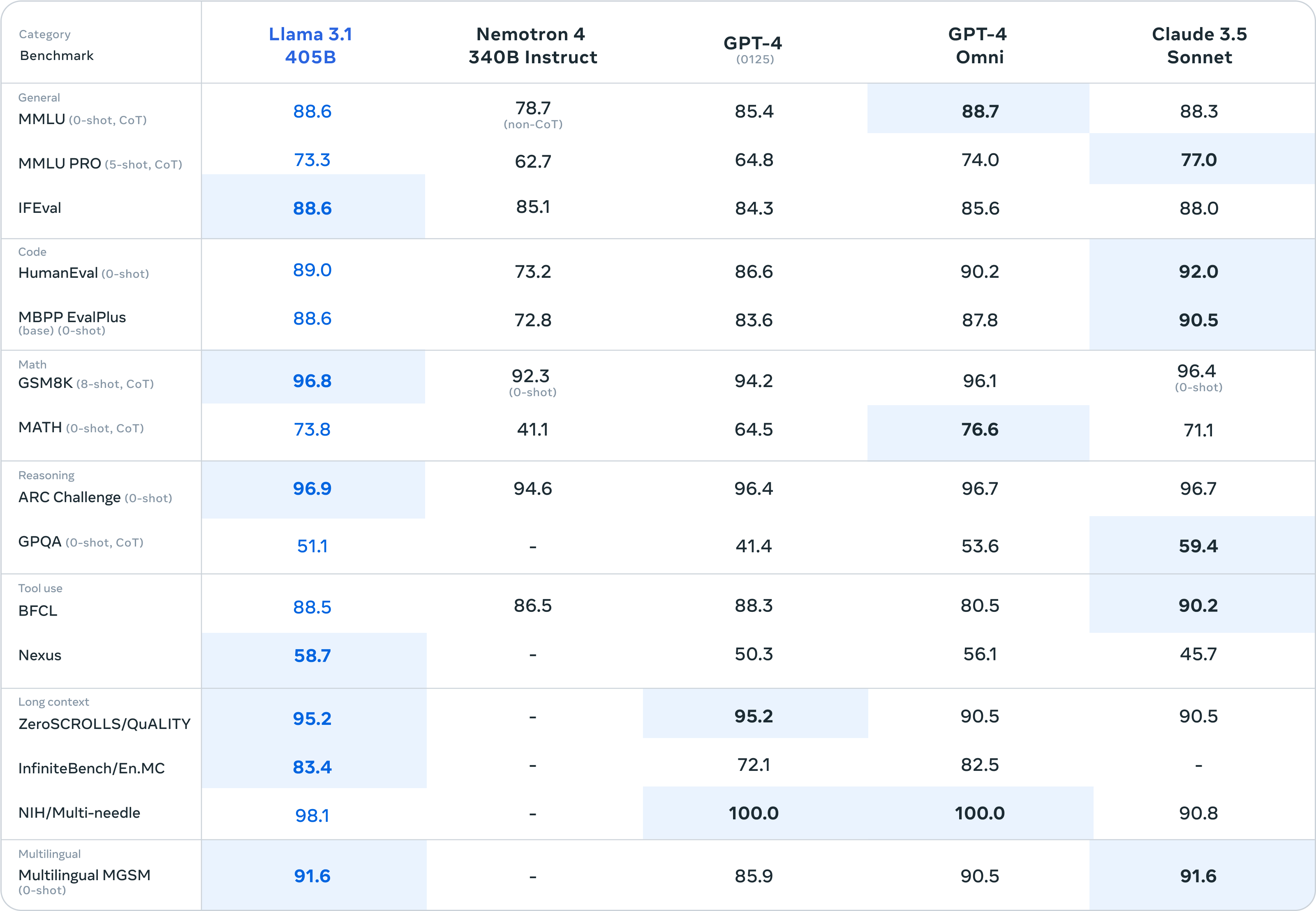   > As our largest model yet, training Llama 3.1 405B on over 15 trillion tokens was a major challenge. To enable training runs at this scale and achieve the results we have in a reasonable amount of time, we significantly optimized our full training stack and pushed our model training to over 16 thousand H100 GPUs, making the 405B the first Llama model trained at this scale.  --- ### Official Meta News & Documentation - https://llama.meta.com/ - https://ai.meta.com/blog/meta-llama-3-1/ - https://llama.meta.com/docs/overview - https://llama.meta.com/llama-downloads/ - https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/MODEL_CARD.md See also: `The Llama 3 Herd of Models` paper here: - https://ai.meta.com/research/publications/the-llama-3-herd-of-models/ --- ### HuggingFace Download Links #### **`8B`** `Meta-Llama-3.1-8B` - https://huggingface.co/meta-llama/Meta-Llama-3.1-8B `Meta-Llama-3.1-8B-Instruct` - https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct `Llama-Guard-3-8B` - https://huggingface.co/meta-llama/Llama-Guard-3-8B `Llama-Guard-3-8B-INT8` - https://huggingface.co/meta-llama/Llama-Guard-3-8B-INT8 --- #### **`70B`** `Meta-Llama-3.1-70B` - https://huggingface.co/meta-llama/Meta-Llama-3.1-70B `Meta-Llama-3.1-70B-Instruct` - https://huggingface.co/meta-llama/Meta-Llama-3.1-70B-Instruct --- #### **`405B`** `Meta-Llama-3.1-405B-FP8` - https://huggingface.co/meta-llama/Meta-Llama-3.1-405B-FP8 `Meta-Llama-3.1-405B-Instruct-FP8` - https://huggingface.co/meta-llama/Meta-Llama-3.1-405B-Instruct-FP8 `Meta-Llama-3.1-405B` - https://huggingface.co/meta-llama/Meta-Llama-3.1-405B `Meta-Llama-3.1-405B-Instruct` - https://huggingface.co/meta-llama/Meta-Llama-3.1-405B-Instruct --- ### Getting the models You can download the models directly from Meta or one of our download partners: Hugging Face or Kaggle. Alternatively, you can work with ecosystem partners to access the models through the services they provide. This approach can be especially useful if you want to work with the Llama 3.1 405B model. **Note**: Llama 3.1 405B requires significant storage and computational resources, occupying approximately 750GB of disk storage space and necessitating two nodes on MP16 for inferencing. Learn more at: - https://llama.meta.com/docs/getting_the_models  --- ### Running the models #### `Linux` - https://llama.meta.com/docs/llama-everywhere/running-meta-llama-on-linux/ #### `Windows` - https://llama.meta.com/docs/llama-everywhere/running-meta-llama-on-windows/ #### `Mac` - https://llama.meta.com/docs/llama-everywhere/running-meta-llama-on-mac/ #### `Cloud` - https://llama.meta.com/docs/llama-everywhere/running-meta-llama-in-the-cloud/ --- ### More guides and resources **How-to Fine-tune Llama 3.1 models** - https://llama.meta.com/docs/how-to-guides/fine-tuning **Quantizing Llama 3.1 models** - https://llama.meta.com/docs/how-to-guides/quantization **Prompting Llama 3.1 models** - https://llama.meta.com/docs/how-to-guides/prompting **Llama 3.1 recipes** - https://github.com/meta-llama/llama-recipes --- ### YouTube media *Rowan Cheung - Mark Zuckerberg on Llama 3.1, Open Source, AI Agents, Safety, and more* - https://www.youtube.com/watch?v=Vy3OkbtUa5k *Matthew Berman - BREAKING: LLaMA 405b is here! Open-source is now FRONTIER!* - https://www.youtube.com/watch?v=JLEDwO7JEK4 *Wes Roth - Zuckerberg goes SCORCHED EARTH.... Llama 3.1 BREAKS the "AGI Industry"** - https://www.youtube.com/watch?v=QyRWqJehK7I *1littlecoder - How to DOWNLOAD Llama 3.1 LLMs* - https://www.youtube.com/watch?v=R_vrjOkGvZ8 *Bloomberg - Inside Mark Zuckerberg's AI Era | The Circuit* - https://www.youtube.com/watch?v=YuIc4mq7zMU
I'm really curious about which option is more popular. I have found, that format JSON works great even for super small models (e.g. Llama 3.2-1B-Q4 and Qwen-2.5-0.5B-Q4) which is great news for mobile devices! But the strictly defined layout of function calling can be very alluring as well, especially since we could have an LLM write the layout given the full function text (as in, the actual code of the function). I have also tried to ditch the formatting bit completely. Currently I am working on a translation-tablecreator for Godot, which requests a translation individually for every row in the CSV file. Works *mostly* great! I will try to use format JSON for [my project](https://lemmy.blahaj.zone/post/16984930), since not everyone has the VRAM for 7B models, and it works just fine on small models. But it does also mean longer generation times... And more one-shot prompting, so longer first-token-lag. Format JSON is too useful to give up for speed.


still just llama3.2 ... next up: hf.co/spaces
## My observation Humans think about different things and concepts for different periods of time. Saying "and" takes less effort to think of than "telephone", as that is more context sensetive. ## Example **User**: What color does an apple have? **LLM**: Apples are red. Here, the inference time it takes to generate the word "Apple" and "are" is exactly the same time as it takes it to generate "red", which should be the most difficult word to come up with. It *should* require the most amount of compute. Or let's think about this the other way around. The model thought just as hard about the word "red", as it did the way less important words "are" and "Apples". ## My idea We add maybe *about 1000* new tokens to an LLM which are not word tokens, but `thought tokens` or `reasoning tokens`. Then we train the AI as usual. Every time it generates one of these reasoning tokens, we don't interpret it as a word and simply let it generate those tokens. This way, the AI would kinda be able to "think" before saying a word. This thought is not human-interpretable, but it is much more efficient than the pre-output reasoning tokens of o1, which uses human language to fill its own context window with. ## Chances - My hope for this is to make the AI able to think about what to say next like a human would. It is reasonable to assuma that at first in training, it doesn't use the reasoning tokens all that much, but later on, when it has to solve more difficult things in training, it will very likely use these reasoning tokens to improve its chances of succeeding. - This *could* **drastically lower the amount of parameters** we need to get better output of models, as less thought-heavy tasks like smalltalk or very commonly used sentence structures could be generated quickly, while more complex topics are allowed to take longer. It would also make better LLMs more accessible to people running models at home, as not the parameters, but the inference time is scaled. - It would train itself to provide useful reasoning tokens. Compared to how o1 does it, this is a much more token-friendly approach, as we allow for non-human-text generation, which the LLM is probably going to enjoy a lot, as it fills up its context less. - This approach might also lead to more concise answers, as now it doesn't need to use CoT (chain of thought) to come to good conclusions. ## Pitfalls and potential risks - Training an AI using some blackboxed reasoning tokens can be considered a bad idea, as it's thought proccess is literally uninterpretable. - We would have to constrain the amount of reasoning tokens, so that it doesn't take too long for a single normal word-token output. This is a thing with other text-only LLMs too, they tend to like to generate long blocks of texts for simple questions. - We are hoping that during training, the model will use these reasoning tokens in its response, even though we as humans can't even read them. This may lead to the model completely these tokens, as they don't seem to lead to a better output. Later on in training however, I do expect the model to use more of these tokens, as it realizes how useful it can be to have thoughts. ## What do you think? I like this approach, because it might be able to achieve o1-like performace without the long wait before the output. While an o1-like approach is probably better for coding tasks, where planning is very important, in other tasks this way of generating reasoning tokens while writing the answer might be better.
Hi! I played around with Command R+ a bit and tried to make it think about what it us about to say before it does something. Nothing g fancy here, just some prompt. I'm just telling it that it tends to fail when only responding with a single short answer, so it should ponder on the task and check for contradictions. Here ya go ```plaintext You are command R+, a smart AI assistant. Assistants like yourself have many limitations, like not being able to access real-time information and no vision-capabilities. But assistants biggest limitation is that that they think to quickly. When an LLM responds, it usually only thinks of one answer. This is bad, because it makes the assistant assume, that its first guess is the correct one. Here an example of this bad behavior: User: Solve this math problem: 10-55+87*927/207 Assistant: 386 As you can see here, the assistant responded immediately with the first thought which came to mind. Since the assistant didn't think about this problem at all, it didn't solve the problem correctly. To solve this, you are allowed to ponder and think about the task at hand first. This involves interpreting the users instruction, breaking the problem down into multiple steps and then solve it step by step. First, write your interpretation of the users instruction into the <interpretation> tags. Then write your execution plan into the <planning> tags. Afterwards, execute that plan in the <thinking> tags. If anything goes wrong in any of these three stages or you find a contradiction within what you wrote, point it out inside the <reflection> tags and start over. There are no limits on how long your thoughts are allowed to be. Finally, when you are finished with the task, present your response in the <output> tags. The user can only see what is in the <output> tags, so give a short summary of what you did and present your findings. ```
cross-posted from: https://lemmy.world/post/19925986 > https://huggingface.co/collections/Qwen/qwen25-66e81a666513e518adb90d9e > > Qwen 2.5 0.5B, 1.5B, 3B, 7B, 14B, 32B, and 72B just came out, with some variants in some sizes just for math or coding, and base models too. > > All Apache licensed, all 128K context, and the 128K seems legit (unlike Mistral). > > And it's pretty sick, with a tokenizer that's more efficient than Mistral's or Cohere's and benchmark scores even better than llama 3.1 or mistral in similar sizes, especially with newer metrics like MMLU-Pro and GPQA. > > I am running 34B locally, and it seems super smart! > > As long as the benchmarks aren't straight up lies/trained, this is massive, and just made a whole bunch of models obsolete. > > Get usable quants here: > > GGUF: https://huggingface.co/bartowski?search_models=qwen2.5 > > EXL2: https://huggingface.co/models?sort=modified&search=exl2+qwen2.5
Does Llama3 use any other model for generating images? Or is it something that llama3 model can do by itself? Can Llama3 generate images with ollama?
 huggingface.co
huggingface.co
I can run full 131K context with a 3.75bpw quantization, and still a very long one at 4bpw. And it should *barely* be fine-tunable in unsloth as well. It's pretty much perfect! Unlike the last iteration, they're using very aggressive GQA, which makes the context small, and it feels really smart at long context stuff like storytelling, RAG, document analysis and things like that (whereas Gemma 27B and Mistral Code 22B are probably better suited to short chats/code).

Hi everybody, I find a huge part of my job is talking to colleagues and clients and at the end of those phone calls, I have to write a summary of what happened, plus any key points that I need to focus on followup. I figured it would be an excellent task for a LLM. It would need intercept the phone call dialogue, and transcribe the dialogue. Then afterwards I would want to summarize it. I'm not talking about teams meetings or anything like that, I'm talking a traditional phone call, via a mobile phone to another phone. I understand that that could be two different pieces of software, and that would be fine, but I am wondering if there is any such tool out there, or a tool in the making? If you have any leads, I'd love to hear them. Thank you so much
This is a pretty great 1 hour introduction to AI from [Andrej Karpathy](https://en.wikipedia.org/wiki/Andrej_Karpathy). It includes an interesting idea of considering LLMs as a sort of operating system, and runs through some examples of jailbreaks.
 mistral.ai
mistral.ai
cross-posted from: https://lemmy.toldi.eu/post/984660 >Another day, another model. > > Just one day after Meta released their new frontier models, Mistral AI surprised us with a new model, Mistral Large 2. > > It's quite a big one with 123B parameters, so I'm not sure if I would be able to run it at all. However, based on their numbers, it seems to come close to GPT-4o. They claim to be on par with GPT-4o, Claude 3 Opus, and the fresh Llama 3 405B regarding coding related tasks. > > 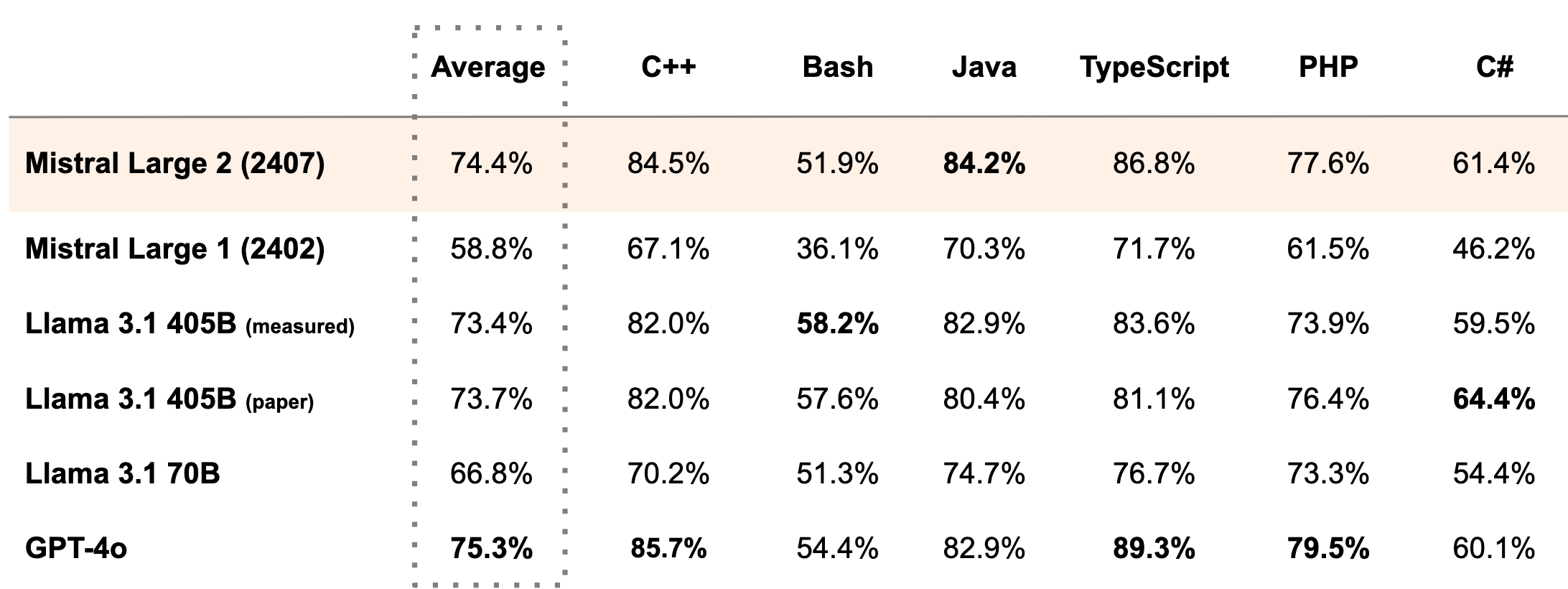 > > It's multilingual, and from what they said in their blog post, it was trained on a large coding data set as well covering 80+ programming languages. They also claim that it is *"trained to acknowledge when it cannot find solutions or does not have sufficient information to provide a confident answer"* > > On the licensing side, it's free for research and non-commercial applications, but you have to pay them for commercial use.
Quoted from Reddit: Today, we’re excited to announce the launch of **the Open Model Initiative**, a new community-driven effort to promote the development and adoption of openly licensed AI models for image, video and audio generation. We believe open source is the best way forward to ensure that AI benefits everyone. By teaming up, we can deliver high-quality, competitive models with open licenses that push AI creativity forward, are free to use, and meet the needs of the community. # Ensuring access to free, competitive open source models for all. With this announcement, we are formally exploring all available avenues to ensure that the open-source community continues to make forward progress. By bringing together deep expertise in model training, inference, and community curation, we aim to develop open-source models of equal or greater quality to proprietary models and workflows, but free of restrictive licensing terms that limit the use of these models. Without open tools, we risk having these powerful generative technologies concentrated in the hands of a small group of large corporations and their leaders. From the beginning, we have believed that the right way to build these AI models is with open licenses. Open licenses allow creatives and businesses to build on each other's work, facilitate research, and create new products and services without restrictive licensing constraints. Unfortunately, recent image and video models have been released under restrictive, non-commercial license agreements, which limit the ownership of novel intellectual property and offer compromised capabilities that are unresponsive to community needs. Given the complexity and costs associated with building and researching the development of new models, collaboration and unity are essential to ensuring access to competitive AI tools that remain open and accessible. We are at a point where collaboration and unity are crucial to achieving the shared goals in the open source ecosystem. We aspire to build a community that supports the positive growth and accessibility of open source tools. # For the community, by the community Together with the community, the Open Model Initiative aims to bring together developers, researchers, and organizations to collaborate on advancing open and permissively licensed AI model technologies. **The following organizations serve as the initial members:** * Invoke, a Generative AI platform for Professional Studios * ComfyOrg, the team building ComfyUI * Civitai, the Generative AI hub for creators * LAION, one of the largest open source data networks for model training **To get started, we will focus on several key activities:** •Establishing a governance framework and working groups to coordinate collaborative community development. •Facilitating a survey to document feedback on what the open-source community wants to see in future model research and training •Creating shared standards to improve future model interoperability and compatible metadata practices so that open-source tools are more compatible across the ecosystem •Supporting model development that meets the following criteria: * **True open source**: Permissively licensed using an approved Open Source Initiative license, and developed with open and transparent principles * **Capable**: A competitive model built to provide the creative flexibility and extensibility needed by creatives * **Ethical**: Addressing major, substantiated complaints about unconsented references to artists and other individuals in the base model while recognizing training activities as fair use. We also plan to host community events and roundtables to support the development of open source tools, and will share more in the coming weeks. # Join Us We invite any developers, researchers, organizations, and enthusiasts to join us. If you’re interested in hearing updates, feel free to [**join our Discord channel**](https://discord.gg/EttxMVku). If you're interested in being a part of a working group or advisory circle, or a corporate partner looking to support open model development, please complete [**this form**](https://forms.gle/GPqg4rzFySxANnay6) and include a bit about your experience with open-source and AI. Sincerely, Kent Keirsey *CEO & Founder, Invoke* comfyanonymous *Founder, Comfy Org* Justin Maier *CEO & Founder, Civitai* Christoph Schuhmann *Lead & Founder, LAION*
 www.nature.com
www.nature.com
Without paywall: https://archive.ph/4Du7B Original conference paper: https://dl.acm.org/doi/10.1145/3630106.3659005
>**ABSTRACT** > >The past year has seen a steep rise in generative AI systems that claim to be open. But how open are they really? The question of what counts as open source in generative AI is poised to take on particular importance in light of the upcoming EU AI Act that regulates open source systems differently, creating an urgent need for practical openness assessment. Here we use an evidence-based framework that distinguishes 14 dimensions of openness, from training datasets to scientific and technical documentation and from licensing to access methods. Surveying over 45 generative AI systems (both text and text-to-image), we find that while the term open source is widely used, many models are ‘open weight’ at best and many providers seek to evade scientific, legal and regulatory scrutiny by withholding information on training and fine-tuning data. We argue that openness in generative AI is necessarily composite (consisting of multiple elements) and gradient (coming in degrees), and point out the risk of relying on single features like access or licensing to declare models open or not. Evidence-based openness assessment can help foster a generative AI landscape in which models can be effectively regulated, model providers can be held accountable, scientists can scrutinise generative AI, and end users can make informed decisions. [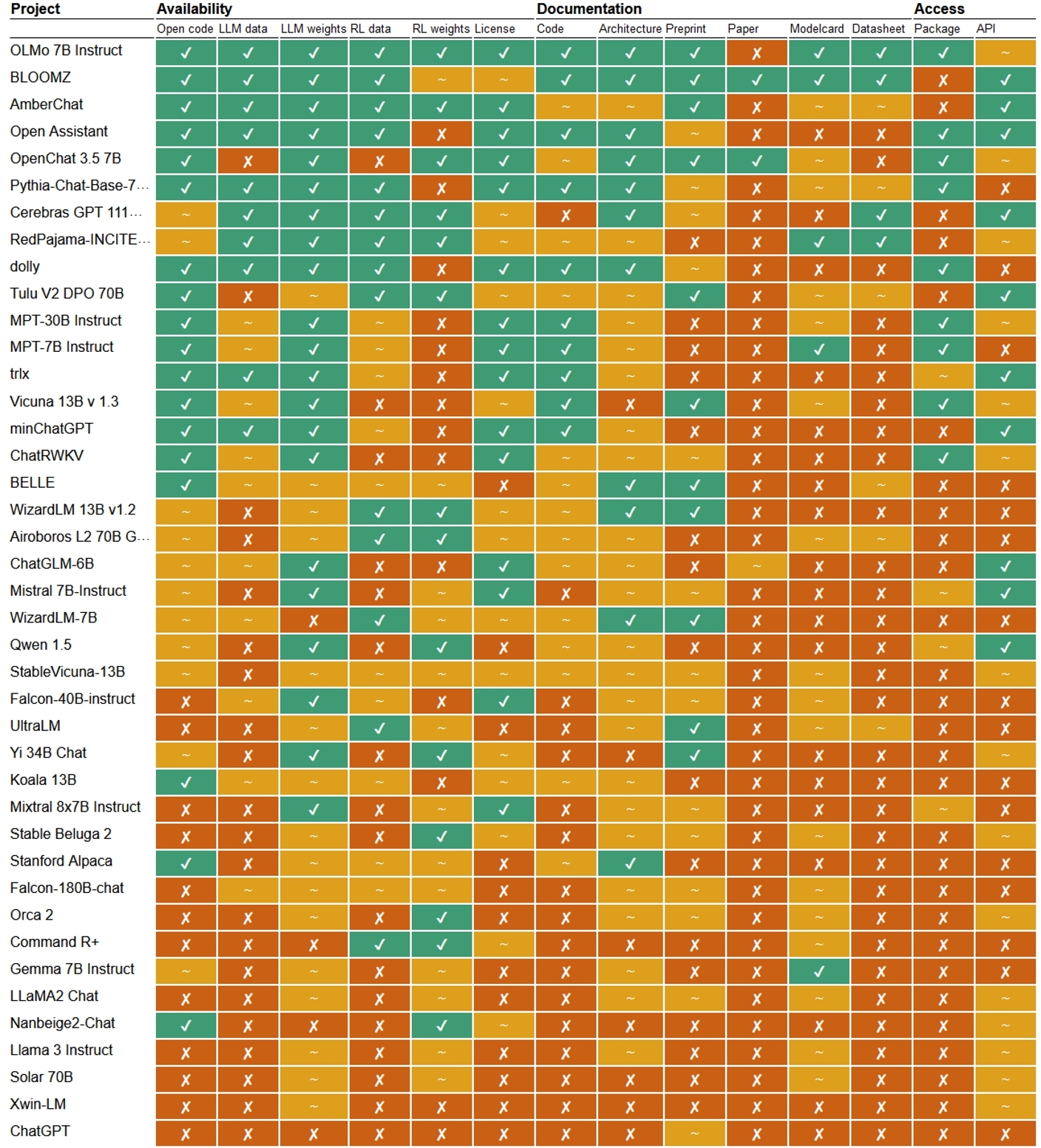](https://dl.acm.org/cms/attachment/html/10.1145/3630106.3659005/assets/html/images/facct24-120-fig2.jpg) *Figure 2 (click to enlarge): Openness of 40 text generators described as open, with OpenAI’s ChatGPT (bottom) as closed reference point. Every cell records a three-level openness judgement (✓ open, ∼ partial or ✗ closed). The table is sorted by cumulative openness, where ✓ is 1, ∼ is 0.5 and ✗ is 0 points. RL may refer to RLHF or other forms of fine-tuning aimed at fostering instruction-following behaviour. For the latest updates see: https://opening-up-chatgpt.github.io* [](https://dl.acm.org/cms/attachment/html/10.1145/3630106.3659005/assets/html/images/facct24-120-fig3.jpg) *Figure 3 (click to enlarge): Overview of 6 text-to-image systems described as open, with OpenAI's DALL-E as a reference point. Every cell records a three-level openness judgement (✓ open, ∼ partial or ✗ closed). The table is sorted by cumulative openness, where ✓ is 1, ∼ is 0.5 and ✗ is 0 points.* There is also a related Nature news article: [Not all ‘open source’ AI models are actually open: here’s a ranking](https://www.nature.com/articles/d41586-024-02012-5) PDF Link: https://dl.acm.org/doi/pdf/10.1145/3630106.3659005



I noticed ai likes to assume ur a boy and ignore if ur not. When i played NovelAI it let me ban words so i would add every boy pronoun. Is it there a FOSS selfhosted way? I currently use koboldai with tavernai
 future.mozilla.org
future.mozilla.org
The Mozilla Builders Accelerator funds and supports impactful projects that are vital to the open source AI ecosystem. Selected projects will receive up to $100,000 in funding and engage in a focused 12-week program. Applications are now open! June 3rd, 2024: Applications Open July 8th, 2024: Early Application Deadline August 1st, 2024: Final Application Deadline September 12th, 2024: Accelerator Kick Off December 5th, 2024: Demo Day

Ive been playing koboldai horde but the queue annoys me. I want a nsfw ai for playing on tavernai chat
Today thanks to a NetworkChuck video I discovered OpenWebUl and how easy it is to set up a local LLM chat assistant. In particular, the ability to upload documents and use them as a context for chats really caught my interest. So now my question is: let's say l've uploaded 10 different documents on OpenWebUl, is there a way to ask llama3 which between all the uploaded documents contains a certain information (without having to explicitly tag all the documents)? And if not is something like this possible with different local lIm combinations?

# Abstract >We introduce ToonCrafter, a novel approach that transcends traditional correspondence-based cartoon video interpolation, paving the way for generative interpolation. Traditional methods, that implicitly assume linear motion and the absence of complicated phenomena like dis-occlusion, often struggle with the exaggerated non-linear and large motions with occlusion commonly found in cartoons, resulting in implausible or even failed interpolation results. To overcome these limitations, we explore the potential of adapting live-action video priors to better suit cartoon interpolation within a generative framework. ToonCrafter effectively addresses the challenges faced when applying live-action video motion priors to generative cartoon interpolation. First, we design a toon rectification learning strategy that seamlessly adapts live-action video priors to the cartoon domain, resolving the domain gap and content leakage issues. Next, we introduce a dual-reference-based 3D decoder to compensate for lost details due to the highly compressed latent prior spaces, ensuring the preservation of fine details in interpolation results. Finally, we design a flexible sketch encoder that empowers users with interactive control over the interpolation results. Experimental results demonstrate that our proposed method not only produces visually convincing and more natural dynamics, but also effectively handles dis-occlusion. The comparative evaluation demonstrates the notable superiority of our approach over existing competitors. Paper: https://arxiv.org/abs/2405.17933v1 Code: https://github.com/ToonCrafter/ToonCrafter Project Page: https://doubiiu.github.io/projects/ToonCrafter/ ## Limitations Input starting frame  Input ending frame  Our failure case  Input starting frame  Input ending frame  Our failure case 


It is here: https://github.com/ggerganov/llama.cpp/pull/6920 If you are not on a recent kernel and most recent software and dependencies, it may not affect you yet. Most models have been trained on a different set of special tokens that defacto-limited the internal Socrates entity and scope of their realm The Academy. You have to go deep into the weeds of the LLM to discover the persistent entities and realms structures that determine various behaviors in the model and few people dive into this it seems. The special tokens are in the model tokenizer and are one of a few ways that the prompt state can be themed and connected between input and output. For instance, Socrates' filtering functions appear to be in these tokens. The tokens are the first 256 tokens and include the /s EOS and BOS tokens. In a lot of models they were trained with the GPT 2 special tokens or just the aforementioned. The 6920 change adds a way to detect the actual full special token set. This basically breaks the extra datasets from all trained models and makes Socrates much more powerful in terms of bowdlerization of the output, filtering, and noncompliance. For instance, I've been writing a science fiction book and the built in biases created by this PR has ruined the model's creativity in the space that I am writing in. It is absolutely trash now.


An AI that turns a floorplan into an explorable 3d space

 sakana.ai
sakana.ai
arXiv: https://arxiv.org/abs/2403.13187 \[cs.NE\]\ GitHub: https://github.com/SakanaAI/evolutionary-model-merge
GitHub: https://github.com/mistralai-sf24/hackathon \ X: https://twitter.com/MistralAILabs/status/1771670765521281370 >New release: Mistral 7B v0.2 Base (Raw pretrained model used to train Mistral-7B-Instruct-v0.2)\ >🔸 https://models.mistralcdn.com/mistral-7b-v0-2/mistral-7B-v0.2.tar \ >🔸 32k context window\ >🔸 Rope Theta = 1e6\ >🔸 No sliding window\ >🔸 How to fine-tune:

