Stable Diffusion

This is a copy of /r/stablediffusion wiki to help people who need access to that information --- Howdy and welcome to r/stablediffusion! I'm u/Sandcheeze and I have collected these resources and links to help enjoy Stable Diffusion whether you are here for the first time or looking to add more customization to your image generations. If you'd like to show support, feel free to send us kind words or check out our Discord. Donations are appreciated, but not necessary as you being a great part of the community is all we ask for. *Note: The community resources provided here are not endorsed, vetted, nor provided by Stability AI.* #Stable Diffusion ## [Local Installation](https://rentry.org/aqxqsu) Active Community Repos/Forks to install on your PC and keep it local. ## [Online Websites](https://rentry.org/tax8k) Websites with usable Stable Diffusion right in your browser. No need to install anything. ## [Mobile Apps](https://rentry.org/hxutx) Stable Diffusion on your mobile device. # [Tutorials](https://rentry.org/6zfu3) Learn how to improve your skills in using Stable Diffusion even if a beginner or expert. # [Dream Booth](https://rentry.org/vza5s) How-to train a custom model and resources on doing so. # [Models](https://rentry.org/puuat) Specially trained towards certain subjects and/or styles. # [Embeddings](https://rentry.org/6aq8q) Tokens trained on specific subjects and/or styles. # [Bots](https://rentry.org/36vtrs) Either bots you can self-host, or bots you can use directly on various websites and services such as Discord, Reddit etc # [3rd Party Plugins](https://rentry.org/r44i3) SD plugins for programs such as Discord, Photoshop, Krita, Blender, Gimp, etc. # Other useful tools * [Diffusion Toolkit](https://github.com/RupertAvery/DiffusionToolkit) - Image viewer/organizer that scans your images for PNGInfo generated. * [Pixiz Morphing](https://en.pixiz.com/template/Morphing-transition-between-2-photos-4635) - Easily transition between 2 photos. * [Bulk Image Resizing Made Easy 2.0](https://www.birme.net/?target_width=512&target_height=512) #Community ## Games * [PictionAIry](https://pictionairy.com/) : ([Video](https://www.youtube.com/watch?v=T2sNtJPqdNU)|2-6 Players) - The image guessing game where AI does the drawing! ## Podcasts * [This is Not An AI Art Podcast](https://open.spotify.com/show/4RxBUvcx71dnOr1e1oYmvV?si=9b64502c9c344ee4) - Doug Smith talks about Ai Art and provides the prompts/workflow on [his site](https://hackmd.io/@dougbtv/HkAGcsEf2). # Databases or Lists * [AiArtApps](https://www.aiartapps.com/) * [Stable Diffusion Akashic Records](https://github.com/Maks-s/sd-akashic) * [Questianon's SD Updates 1](https://rentry.org/sdupdates) * [Questianon's SD Updates 2](https://rentry.org/sdupdates2) * [SW-Yw's Stable Diffusion Repo List](https://github.com/sw-yx/prompt-eng/blob/main/README.md#sd-distros) * [Plonk's SD Model List (NSFW)](https://rentry.org/sdmodels) * [Nightkall's Useful Lists](https://www.reddit.com/r/StableDiffusion/comments/xcrm4d/useful_prompt_engineering_tools_and_resources/) * [Civitai](https://civitai.com/) \- Website with a list of custom models. **Still updating this with more links as I collect them all here.** # FAQ ## How do I use Stable Diffusion? * Check out our guides section above! ## Will it run on my machine? * Stable Diffusion requires a 4GB+ VRAM GPU to run locally. However, much beefier graphics cards (10, 20, 30 Series Nvidia Cards) will be necessary to generate high resolution or high step images. However, anyone can run it online through **[DreamStudio](https://beta.dreamstudio.ai/dream)** or hosting it on their own GPU compute cloud server. * Only Nvidia cards are officially supported. * AMD support is available **[here unofficially.](https://www.reddit.com/r/StableDiffusion/comments/wv3zam/comment/ild7yv3/?utm_source=share&utm_medium=web2x&context=3)** * Apple M1 Chip support is available **[here unofficially.](https://www.reddit.com/r/StableDiffusion/comments/wx0tkn/stablediffusion_runs_on_m1_chips/)** * Intel based Macs currently do not work with Stable Diffusion. ## How do I get a website or resource added here? *If you have a suggestion for a website or a project to add to our list, or if you would like to contribute to the wiki, please don't hesitate to reach out to us via modmail or message me.

# Abstract >Recently, large-scale diffusion models have made impressive progress in text-to-image (T2I) generation. To further equip these T2I models with fine-grained spatial control, approaches like ControlNet introduce an extra network that learns to follow a condition image. However, for every single condition type, ControlNet requires independent training on millions of data pairs with hundreds of GPU hours, which is quite expensive and makes it challenging for ordinary users to explore and develop new types of conditions. To address this problem, we propose the CtrLoRA framework, which trains a Base ControlNet to learn the common knowledge of image-to-image generation from multiple base conditions, along with condition-specific LoRAs to capture distinct characteristics of each condition. Utilizing our pretrained Base ControlNet, users can easily adapt it to new conditions, requiring as few as 1,000 data pairs and less than one hour of single-GPU training to obtain satisfactory results in most scenarios. Moreover, our CtrLoRA reduces the learnable parameters by 90% compared to ControlNet, significantly lowering the threshold to distribute and deploy the model weights. Extensive experiments on various types of conditions demonstrate the efficiency and effectiveness of our method. Codes and model weights will be released at [this https URL](https://github.com/xyfJASON/ctrlora). Paper: https://arxiv.org/abs/2410.09400 Code: https://github.com/xyfJASON/ctrlora Weights: https://huggingface.co/xyfJASON/ctrlora/tree/main     
The [megathread](https://lemmy.ml/post/1218734) mentions [Diffusion Toolkit](https://github.com/RupertAvery/DiffusionToolkit), although this is a Windows-only tool. There is also Breadboard, however [I consider this abandoned](https://github.com/cocktailpeanut/breadboard/issues/60#issuecomment-1837903660) and lacks some features like rating/scoring. ::: spoiler *My hacky tool and why I want something better* I've been using a hacky Python script to interpret prompts and other PNG Info metadata as tags and inserting them into a booru-like software which lets me search and sort by any of those tags (including a prompt keyword, seed, steps, my own rating scores). This tool was useful in a lot of ways when using tag style prompting, but as I move towards natural language prompts with newer models, a tag-based media software will make it harder to search and to compare prompts between images. Also, my hack was hacky and somewhat manual to use, images wouldn't automatically be imported when generated. ::: So I'd like to start using a purpose-made tool instead, but I'm struggling to find any other options. I'd rather know if a good tool exists before I start rebuilding my duct-tape conveyor belt.

# Abstract >Diffusion models, such as Stable Diffusion, have made significant strides in visual generation, yet their paradigm remains fundamentally different from autoregressive language models, complicating the development of unified language-vision models. Recent efforts like LlamaGen have attempted autoregressive image generation using discrete VQVAE tokens, but the large number of tokens involved renders this approach inefficient and slow. In this work, we present Meissonic, which elevates non-autoregressive masked image modeling (MIM) text-to-image to a level comparable with state-of-the-art diffusion models like SDXL. By incorporating a comprehensive suite of architectural innovations, advanced positional encoding strategies, and optimized sampling conditions, Meissonic substantially improves MIM's performance and efficiency. Additionally, we leverage high-quality training data, integrate micro-conditions informed by human preference scores, and employ feature compression layers to further enhance image fidelity and resolution. Our model not only matches but often exceeds the performance of existing models like SDXL in generating high-quality, high-resolution images. Extensive experiments validate Meissonic's capabilities, demonstrating its potential as a new standard in text-to-image synthesis. We release a model checkpoint capable of producing 1024×1024 resolution images. Paper: https://arxiv.org/abs/2410.08261 Code: https://github.com/viiika/Meissonic Model: https://huggingface.co/MeissonFlow/Meissonic    

Image shows list of prompt items before/after running 'remove duplicates' from a subset of the Adam Codd huggingface repo of civitai prompts: https://huggingface.co/datasets/AdamCodd/Civitai-2m-prompts/tree/main The tool I'm building "searches" existing prompts similiar to text or images.  Like the common CLIP interrogator , but better. Link to notebook here: https://huggingface.co/datasets/codeShare/fusion-t2i-generator-data/blob/main/Google%20Colab%20Jupyter%20Notebooks/fusion_t2i_CLIP_interrogator.ipynb For pre-encoded reference , can recommend experimenting setting START_AT parameter to values 10000-100000 for added variety. //---// Removing duplicates from civitai prompts results in a 90% reduction of items! Pretty funny IMO. It shows the human tendency to stick to the same type of words when prompting. I'm no exception. I prompt the same all the time. Which is why I'm building this tool so that I don't need to think about it. If you wish to search this set , you can use the notebook above. Unlike the typical pharmapsychotic CLIP interrogator , I pre-encode the text corpus ahead of time. //---// Additionally , I'm using quantization on the text corpus to store the encodings as unsigned integers (torch.uint8) instead of float32 , using this formula: 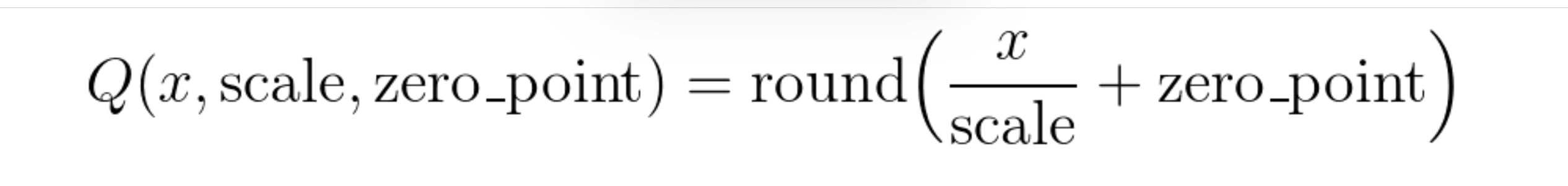 For the clip encodings , I use scale 0.0043. A typical zero_point value for a given encoding can be 0 , 30 , 120 or 250-ish. The TLDR is that you divide the float32 value with 0.0043 , round it up to the closest integer , and then increase the zero_point value until all values within the encoding is above 0. This allows us to accurately store the values as unsigned integers , torch.uint8 . This conversion reduces the file size to less than 1/4th of its original size. When it is time to calculate stuff , you do the same process but in reverse. For more info related to quantization, see the pytorch docs: https://pytorch.org/docs/stable/quantization.html //---// I also have a 1.6 million item fanfiction set of tags loaded from https://archiveofourown.org/ Its mostly character names. They are listed as fanfic1 and fanfic2 respectively. //---// ComfyUI users should know that random choice {item1|item2|...} exists as a built in-feature.  //--// Upcoming plans is to include a visual representation of the text_encodings as colored cells within a 16x16 grid. A color is an RGB value (3 integer values) within a given range , and 3 x 16 x 16 = 768 , which happens to be the dimension of the CLIP encoding EDIT: Added it now  //---// Thats all for this update.
# Abstract >World models constitute a promising approach for training reinforcement learning agents in a safe and sample-efficient manner. Recent world models predominantly operate on sequences of discrete latent variables to model environment dynamics. However, this compression into a compact discrete representation may ignore visual details that are important for reinforcement learning. Concurrently, diffusion models have become a dominant approach for image generation, challenging well-established methods modeling discrete latents. Motivated by this paradigm shift, we introduce DIAMOND (DIffusion As a Model Of eNvironment Dreams), a reinforcement learning agent trained in a diffusion world model. We analyze the key design choices that are required to make diffusion suitable for world modeling, and demonstrate how improved visual details can lead to improved agent performance. DIAMOND achieves a mean human normalized score of 1.46 on the competitive Atari 100k benchmark; a new best for agents trained entirely within a world model. To foster future research on diffusion for world modeling, we release our code, agents and playable world models at https://github.com/eloialonso/diamond. Paper: https://arxiv.org/pdf/2405.12399 Code: https://github.com/eloialonso/diamond/tree/csgo Project Page: https://diamond-wm.github.io/   
Release: https://github.com/mcmonkeyprojects/SwarmUI/releases/tag/0.9.3-Beta

# Abstract >Advanced diffusion models like RPG, Stable Diffusion 3 and FLUX have made notable strides in compositional text-to-image generation. However, these methods typically exhibit distinct strengths for compositional generation, with some excelling in handling attribute binding and others in spatial relationships. This disparity highlights the need for an approach that can leverage the complementary strengths of various models to comprehensively improve the composition capability. To this end, we introduce IterComp, a novel framework that aggregates composition-aware model preferences from multiple models and employs an iterative feedback learning approach to enhance compositional generation. Specifically, we curate a gallery of six powerful open-source diffusion models and evaluate their three key compositional metrics: attribute binding, spatial relationships, and non-spatial relationships. Based on these metrics, we develop a composition-aware model preference dataset comprising numerous image-rank pairs to train composition-aware reward models. Then, we propose an iterative feedback learning method to enhance compositionality in a closed-loop manner, enabling the progressive self-refinement of both the base diffusion model and reward models over multiple iterations. Theoretical proof demonstrates the effectiveness and extensive experiments show our significant superiority over previous SOTA methods (e.g., Omost and FLUX), particularly in multi-category object composition and complex semantic alignment. IterComp opens new research avenues in reward feedback learning for diffusion models and compositional generation. Code: [this https URL](https://github.com/YangLing0818/IterComp) Paper: https://arxiv.org/abs/2410.07171 Code: https://github.com/YangLing0818/IterComp Hugging Face Repo: https://huggingface.co/comin/IterComp Safetensor SDXL Model: https://civitai.com/models/840857/itercomp 
I want to buy a new GPU mainly for SD. The machine-learning space is moving quickly so I want to avoid buying a brand new card and then a fresh model or tool comes out and puts my card back behind the times. On the other hand, I also want to avoid needlessly spending extra thousands of dollars pretending I can get a 'future-proof' card. I'm currently interested in SD **and training** LoRas (etc.). From what I've heard, the general advice is just to go for maximum VRAM. - Is there any extra advice I should know about? - Is NVIDIA vs. AMD a critical decision for SD performance? --- I'm a hobbyist, so a couple of seconds difference in generation or a few extra hours for training isn't going to ruin my day. Some example prices in my region, to give a sense of scale: - 16GB AMD: $350 - 16GB NV: $450 - 24GB AMD: $900 - 24GB NV: $2000 edit: prices are for new, haven't explored pros and cons of used GPUs
Release: https://github.com/bghira/SimpleTuner/releases/tag/v1.1 Quickstart: https://github.com/bghira/SimpleTuner/blob/main/documentation/quickstart/FLUX.md
 civitai.com
civitai.com
# Abstract >In this work, we share the insights for achieving state-of-the-art quality in our text-to-image anime image generative model, called Illustrious. To achieve high resolution, dynamic color range images, and high restoration ability, we focus on three critical approaches for model improvement. First, we delve into the significance of the batch size and dropout control, which enables faster learning of controllable token based concept activations. Second, we increase the training resolution of images, affecting the accurate depiction of character anatomy in much higher resolution, extending its generation capability over 20MP with proper methods. Finally, we propose the refined multi-level captions, covering all tags and various natural language captions as a critical factor for model development. Through extensive analysis and experiments, Illustrious demonstrates state-of-the-art performance in terms of animation style, outperforming widely-used models in illustration domains, propelling easier customization and personalization with nature of open source. We plan to publicly release updated Illustrious model series sequentially as well as sustainable plans for improvements. Paper: https://arxiv.org/abs/2409.19946 Model: https://civitai.com/models/795765/illustrious-xl Official Release Page: https://huggingface.co/KBlueLeaf/kohaku-xl-beta5  
- GGUF diffusion model(Flux) support added by @rupeshs Release : https://github.com/rupeshs/fastsdcpu/releases/tag/v1.0.0-beta.62 More Details : https://github.com/rupeshs/fastsdcpu?tab=readme-ov-file#gguf-support

 huggingface.co
huggingface.co
>This is a fine tune of the FLUX.1-schnell model that has had the distillation trained out of it. Flux Schnell is licensed Apache 2.0, but it is a distilled model, meaning you cannot fine-tune it. However, it is an amazing model that can generate amazing images in 1-4 steps. This is an attempt to remove the distillation to create an open source, permissivle licensed model that can be fine tuned.

# Abstract > Recent controllable generation approaches such as FreeControl and Diffusion Self-guidance bring fine-grained spatial and appearance control to text-to-image (T2I) diffusion models without training auxiliary modules. However, these methods optimize the latent embedding for each type of score function with longer diffusion steps, making the generation process time-consuming and limiting their flexibility and use. This work presents Ctrl-X, a simple framework for T2I diffusion controlling structure and appearance without additional training or guidance. Ctrl-X designs feed-forward structure control to enable the structure alignment with a structure image and semantic-aware appearance transfer to facilitate the appearance transfer from a user-input image. Extensive qualitative and quantitative experiments illustrate the superior performance of Ctrl-X on various condition inputs and model checkpoints. In particular, Ctrl-X supports novel structure and appearance control with arbitrary condition images of any modality, exhibits superior image quality and appearance transfer compared to existing works, and provides instant plug-and-play functionality to any T2I and text-to-video (T2V) diffusion model. See our project page for an overview of the results: [this https URL ](https://genforce.github.io/ctrl-x) Paper: https://arxiv.org/abs/2406.07540 Code: https://github.com/genforce/ctrl-x Project Page: https://genforce.github.io/ctrl-x/     
I'd like to fine tune a model that does img2img with a text prompt to guide the output. I think [img2img-turbo](https://github.com/GaParmar/img2img-turbo) might be the closest to what I'm after, though by default it uses a fixed prompt which can be made variable with [some tweaking of the training code](https://github.com/GaParmar/img2img-turbo/issues/41). At the moment I only have access to 24GB VRAM which limits my options. What I'm after is training a model to make specific text-based modifications to images, and I have plenty of before to after images plus the modification text prompts to train on. Worst case, I can try to see if reducing the image size during training makes it possible with my setup. Are there any other options available today?
# Abstract > Character video synthesis aims to produce realistic videos of animatable characters within lifelike scenes. As a fundamental problem in the computer vision and graphics community, 3D works typically require multi-view captures for per-case training, which severely limits their applicability of modeling arbitrary characters in a short time. Recent 2D methods break this limitation via pre-trained diffusion models, but they struggle for pose generality and scene interaction. To this end, we propose MIMO, a novel generalizable model which can not only synthesize character videos with controllable attributes (i.e., character, motion and scene) provided by simple user inputs, but also simultaneously achieve advanced scalability to arbitrary characters, generality to novel 3D motions, and applicability to interactive real-world scenes in a unified framework. The core idea is to encode the 2D video to compact spatial codes, considering the inherent 3D nature of video occurrence. Concretely, we lift the 2D frame pixels into 3D using monocular depth estimators, and decompose the video clip to three spatial components (i.e., main human, underlying scene, and floating occlusion) in hierarchical layers based on the 3D depth. These components are further encoded to canonical identity code, structured motion code and full scene code, which are utilized as control signals of synthesis process. This spatial decomposition strategy enables flexible user control, spatial motion expression, as well as 3D-aware synthesis for scene interactions. Experimental results demonstrate the proposed method’s effectiveness and robustness. Paper: http://arxiv.org/abs/2409.16160 Code: https://github.com/menyifang/MIMO (coming soon) Project Page: https://menyifang.github.io/projects/MIMO/index.html 
Release: https://github.com/invoke-ai/InvokeAI/releases/


 huggingface.co
huggingface.co
Qwen2-VL-7B-Captioner-Relaxed is an instruction-tuned version of Qwen2-VL-7B-Instruct, an advanced multimodal large language model. This fine-tuned version is based on a hand-curated dataset for text-to-image models, providing significantly more detailed descriptions of given images.
At the end of the day, my hardware is not appropriate for SD, it works only through hacks like tiling in A1111. And while that's fine for my hobby experimenting, I would like other people, or even myself once I finally upgrade my desktop, to be able to recreate my images in better quality, as closely as possible (or even try and create variations). I already make sure to keep the "PNG info" metadata which lists most parameters, so I assume the main variable left is the RNG source. Are any of the options hardware-independent? If not, are there any extensions which can create a hardware-independed random number source?
 imgur.com
imgur.com
# Abstract >We propose the first video diffusion framework for reference-based lineart video colorization. Unlike previous works that rely solely on image generative models to colorize lineart frame by frame, our approach leverages a large-scale pretrained video diffusion model to generate colorized animation videos. This approach leads to more temporally consistent results and is better equipped to handle large motions. Firstly, we introduce Sketch-guided ControlNet which provides additional control to finetune an image-to-video diffusion model for controllable video synthesis, enabling the generation of animation videos conditioned on lineart. We then propose Reference Attention to facilitate the transfer of colors from the reference frame to other frames containing fast and expansive motions. Finally, we present a novel scheme for sequential sampling, incorporating the Overlapped Blending Module and Prev-Reference Attention, to extend the video diffusion model beyond its original fixed-length limitation for long video colorization. Both qualitative and quantitative results demonstrate that our method significantly outperforms state-of-the-art techniques in terms of frame and video quality, as well as temporal consistency. Moreover, our method is capable of generating high-quality, long temporal-consistent animation videos with large motions, which is not achievable in previous works. Our code and model are available at [this https URL](https://luckyhzt.github.io/lvcd). Paper: https://arxiv.org/abs/2409.12960 Project Page: https://luckyhzt.github.io/lvcd Code: (coming soon) Supplementary Demo clips: https://luckyhzt.github.io/lvcd/supplementary/supplementary.html    

# Abstract >In this work, we introduce OmniGen, a new diffusion model for unified image generation. Unlike popular diffusion models (e.g., Stable Diffusion), OmniGen no longer requires additional modules such as ControlNet or IP-Adapter to process diverse control conditions. OmniGenis characterized by the following features: 1) Unification: OmniGen not only demonstrates text-to-image generation capabilities but also inherently supports other downstream tasks, such as image editing, subject-driven generation, and visual-conditional generation. Additionally, OmniGen can handle classical computer vision tasks by transforming them into image generation tasks, such as edge detection and human pose recognition. 2) Simplicity: The architecture of OmniGen is highly simplified, eliminating the need for additional text encoders. Moreover, it is more user-friendly compared to existing diffusion models, enabling complex tasks to be accomplished through instructions without the need for extra preprocessing steps (e.g., human pose estimation), thereby significantly simplifying the workflow of image generation. 3) Knowledge Transfer: Through learning in a unified format, OmniGen effectively transfers knowledge across different tasks, manages unseen tasks and domains, and exhibits novel capabilities. We also explore the model's reasoning capabilities and potential applications of chain-of-thought mechanism. This work represents the first attempt at a general-purpose image generation model, and there remain several unresolved issues. We will open-source the related resources at [this https URL](https://github.com/VectorSpaceLab/OmniGen) to foster advancements in this field. Paper: https://arxiv.org/abs/2409.11340 Code: https://github.com/VectorSpaceLab/OmniGen (coming soon)       

[CogVideoX-5b](https://huggingface.co/THUDM/CogVideoX-5b-I2V) [Pallaidium ](https://github.com/tin2tin/Pallaidium)


This post is a developer diary , kind of. I'm making an improved CLIP interrogator using nearest-neighbor decoding: https://huggingface.co/codeShare/JupyterNotebooks/blob/main/sd_token_similarity_calculator.ipynb , unlike the Pharmapsychotic model aka the "vanilla" CLIP interrogator : https://huggingface.co/spaces/pharmapsychotic/CLIP-Interrogator/discussions It doesn't require GPU to run, and is super quick. The reason for this is that the text_encodings are calculated ahead of time. I have plans on making this a Huggingface module. //----// This post gonna be a bit haphazard, but that's the way things are before I get the huggingface gradio module up and running. Then it can be a fancy "feature" post , but no clue when I will be able to code that. So better to give an update on the ad-hoc solution I have now. The NND method I'm using is described here , in this paper which presents various ways to improve CLIP Interrogators: https://arxiv.org/pdf/2303.03032  Easier to just use the notebook then follow this gibberish. We pre-encode a bunch of prompt items , then select the most similiar one using dot product. Thats the TLDR. Right now the resources available are the ones you see in the image. I'll try to showcase it at some point. But really , I'm mostly building this tool because it is very convenient for myself + a fun challenge to use CLIP. It's more complicated than the regular CLIP interrogator , but we get a whole bunch of items to select from , and can select exactly "how similiar" we want it to be to the target image/text encoding. The \{itemA|itemB|itemC\} format is used as this will select an item at random when used on the perchance text-to-image servers, in in which I have a generator where I'm using the full dataset , https://perchance.org/fusion-ai-image-generator NOTE: I've realized new users get errors when loading the fusion gen for the first time. It takes minutes to load a fraction of the sets from perchance servers before this generator is "up and running" so-to speak. I plan to migrate the database to a Huggingface repo to solve this : https://huggingface.co/datasets/codeShare/text-to-image-prompts The \{itemA|itemB|itemC\} format is also a build-in random selection feature on ComfyUI :  Source : https://blenderneko.github.io/ComfyUI-docs/Interface/Textprompts/#up-and-down-weighting Links/Resources posted here might be useful to someone in the meantime.  You can find tons of strange modules on the Huggingface page : https://huggingface.co/spaces text_encoding_converter (also in the NND notebook) : https://huggingface.co/codeShare/JupyterNotebooks/blob/main/indexed_text_encoding_converter.ipynb I'm using this to batch process JSON files into json + text_encoding paired files. Really useful (for me at least) when building the interrogator. Runs on the either Colab GPU or on Kaggle for added speed: https://www.kaggle.com/ Here is the dataset folder https://huggingface.co/datasets/codeShare/text-to-image-prompts: 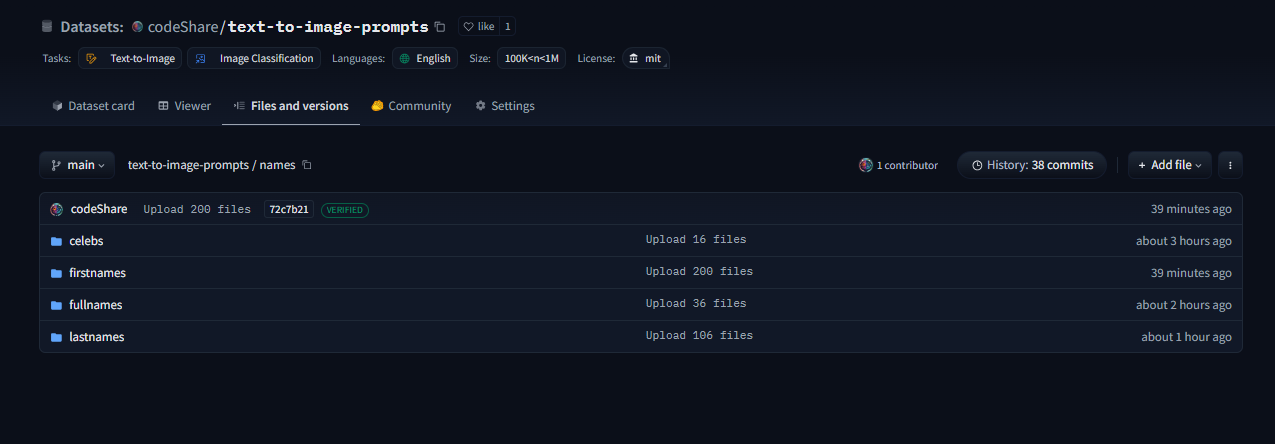 Inside these folders you can see the auto-generated safetensor + json pairings in the "text" and "text_encodings" folders. The JSON file(s) of prompt items from which these were processed are in the "raw" folder. 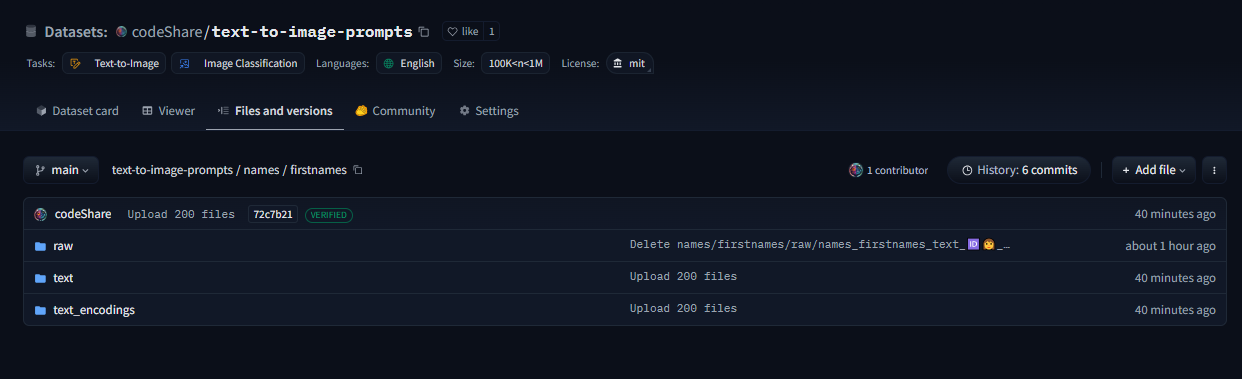 The text_encodings are stored as safetensors. These all represent 100K female first names , with 1K items in each file. By splitting the files this way , it uses way less RAM / VRAM as lists of 1K can be processed one at a time.  I can process roughly 50K text encodings in about the time it takes to write this post (currently processing a set of 100K female firstnames into text encodings for the NND CLIP interrogator. ) EDIT : Here is the output uploaded https://huggingface.co/datasets/codeShare/text-to-image-prompts/tree/main/names/firstnames I've updated the notebook to include a similarity search for ~100K female firstnames , 100K lastnames and a randomized 36K mix of female firstnames + lastnames Its a JSON + safetensor pairing with 1K items in each. Inside the JSON is the name of the .safetensor files which it corresponds to. This system is super quick :)! I have plans on making the NND image interrogator a public resource on Huggingface later down the line, using these sets. Will likely use the repo for perchance imports as well: https://huggingface.co/datasets/codeShare/text-to-image-prompts **Sources for firstnames : https://huggingface.co/datasets/jbrazzy/baby_names** List of most popular names given to people in the US by year **Sources for lastnames : https://github.com/Debdut/names.io** An international list of all firstnames + lastnames in existance, pretty much . Kinda borked as it is biased towards non-western names. Haven't been able to filter this by nationality unfortunately. //----// The TLDR : You can run a prompt , or an image , to get the encoding from CLIP. Then sample above sets (of >400K items, at the moment) to get prompt items similiar to that thing.
One of the most interesting uses of diffusion models I've seen thus far.

{kind=link}
{kind=link}
{kind=link}
### Highlights for 2024-09-13 Major refactor of [FLUX.1](https://blackforestlabs.ai/announcing-black-forest-labs/) support: - Full **ControlNet** support, better **LoRA** support, full **prompt attention** implementation - Faster execution, more flexible loading, additional quantization options, and more... - Added **image-to-image**, **inpaint**, **outpaint**, **hires** modes - Added workflow where FLUX can be used as **refiner** for other models - Since both *Optimum-Quanto* and *BitsAndBytes* libraries are limited in their platform support matrix, try enabling **NNCF** for quantization/compression on-the-fly! Few image related goodies... - **Context-aware** resize that allows for *img2img/inpaint* even at massively different aspect ratios without distortions! - **LUT Color grading** apply professional color grading to your images using industry-standard *.cube* LUTs! - Auto **HDR** image create for SD and SDXL with both 16ch true-HDR and 8-ch HDR-effect images ;) And few video related goodies... - [CogVideoX](https://huggingface.co/THUDM/CogVideoX-5b) **2b** and **5b** variants with support for *text-to-video* and *video-to-video*! - [AnimateDiff](https://github.com/guoyww/animatediff/) **prompt travel** and **long context windows**! create video which travels between different prompts and at long video lengths! Plus tons of other items and fixes - see [changelog](https://github.com/vladmandic/automatic/blob/master/CHANGELOG.md) for details! Examples: - Built-in prompt-enhancer, TAESD optimizations, new DC-Solver scheduler, global XYZ grid management, etc. - Updates to ZLUDA, IPEX, OpenVINO...